Trattamento Automatico del Linguaggio
Una introduzione
Codificare, Analizzare, Diffondere: Le Digital Humanities nei progetti di ricerca
Scuola estiva · Università di Verona
18 luglio 2019
Twitter: #cadottorato19
Greta H. Franzini
Panoramica
- Corso mattino
- Teoria
- Trattamento Automatico del Linguaggio (TAL)
- Linea di comando e Regular Expressions (Regex)
- Pratica
- Linea di comando
- Navigazione file di sistema
- Calcolo della ricchezza lessicale
- TreeTagger
- Testi forniti per esercitazione: due novelle (1878, 1940)
- Laboratorio pomeriggio
- Lavoro sui propri progetti
Teoria
Trattamento Automatico del Linguaggio (TAL)
Natural Language Processing
(NLP)
Cos'è il TAL?
Processo di elaborazione automatica di informazioni scritte o parlate in una lingua naturale
Lingue moderne vs. antiche
Moderne
- Parlate
- Grandi gruppi d'uso
- Grande interesse commerciale
Antiche
- Morte
- Piccoli gruppi d'uso: specialisti
- Poco interesse commerciale
Analisi testuale: mixed method
TAL + umanista
| meccanica | + | interpretazione |
| innovazione | + | tradizione |
Oggi
Informazioni scritte
Risorse linguistiche
Il TAL si avvale di risorse linguistiche = raccolte di dati che documentano atti comunicativi umani
- Corpora
- rappresentativi di una lingua o specialistici
- puro testo o annotati (metadati)
- mono-/multilingue (paralleli/allineati)
- scritti, parlati o misti
- sincronici, diacronici
- Lessici e dizionari
- Tesauri, lessici di valenza, di frequenza, terminologici, etc.
- Ontologie
- rappresentazione formale di concetti
- Grammatiche
Pipeline TAL
l'analisi testuale è complessa
dividere il task di analisi in piccoli subtask risolvibili in modo indipendente da diversi specialisti
Pipeline : modo di progettare un software per cui i risultati di un subtask o modulo alimentano il modulo successivo
One size does not fit all : diverse pipeline per diverse esigenze
Pipeline TAL
- Tokenizzazione
- PoS-tagging e lemmatizzazione
- Analisi morfologica
- Named Entity Recognition (NER)
- Parsing sintattico
- Parsing semantico
- ...

Preprocessing: preparazione dati
Garbage in, garbage out
It is often said that 80% of data analysis is spent on the process of cleaning and preparing the data [...]. Data preparation is not just a first step, but must be repeated many times over the course of analysis as new problems come to light or new data is collected.Hadley Wickham, 2014
Preprocessing: preparazione dati
Formato richiesto:

Pipeline TAL
Tokenizzazione

Suddivisione del testo in token , i.e. unità di analisi:
caratteri, parole, frasi, etc.
Solitamente tokenizzazione per parola
Tokenizzazione
Token ≠ parola
"mangiarmelo"
=
1 token, 3 parole morfologiche
Tokenizzazione
- Type : un lemma, un tipo di token
- Dizionario = insieme di type
- Token : occorrenza di un type in un testo
"Se oggi seren non è doman seren sarà se non sarà seren si rasserenerà"
Token: 14 Type: 9
Tokenizzazione
Hmmm...
"La Spezia"
1 o 2 token?
U.S.A. · ad hoc · Milano-Verona · l’onda · 18.07.2019
Normalizzazione
Verifica dei dati!

PoS-tagging e lemmatizzazione

PoS-tagging : etichettatura linguistica (PoS = Part of Speech)
Lemmatizzazione : riduzione di una forma flessa di una parola alla sua forma canonica, detta lemma (previo PoS-tagging)
PoS-tagging e lemmatizzazione
Tagset : insieme chiuso (set) di etichette (tag) delle parti del discorso usato per annotare il testo (in alcuni casi fino a 200!)
- Parti del discorso:
- sostantivo, verbo, aggettivo, avverbio, articolo, pronome, preposizione, congiunzione, interiezione
- Parti variabili del discorso:
- nome comune/proprio, aggettivo dimostrativo, pronome personale/relativo, etc.
PoS-tagging e lemmatizzazione
Diversi tagset
=Problema di interoperabilità
Standard : Universal Dependencies
PoS-tagging e lemmatizzazione
Metodi
- Rule-based
- Approccio razionalista (intuition based), segue delle regole (supervised)
- Language-dependent
- Molto usato fino agli anni '90
- Data-driven
- Approccio empirista (probabilistic), impara le regole (unsupervised)
- Language independent
- Preso piede dalla seconda metà degli anni '90
- Si avvale di dati annotati
- Ibrido
- TreeTagger
PoS-tagging e lemmatizzazione
TreeTagger
- Tagger fra i più utilizzati
- Supporto per molte lingue, moderne e antiche
- Modelli statistici addestrati (parameter files) gli permettono di stimare la probabilità di transizione da un PoS all'altro
PoS-tagging e lemmatizzazione
Diversi modelli e tagset
"I sensali schioccavan le fruste;"
(Adolfo Albertazzi, Il camiciotto rosso, 1918)
TreeTagger Stein - 38 tag
I DET:def il
sensali NOM sensale
schioccavan VER:impf schioccare
le DET:def il
fruste NOM frusta
; PON ;TreeTagger Baroni - 52 tag
I ART il
sensali NOUN sensale
schioccavan VER:fin schioccare
le ART la
fruste NOUN frusta
; PUN ;PoS-tagging e lemmatizzazione
Ambiguità
TreeTagger (Stein)
alcuni PRO:indef alcun|alcuniTreeTagger (Baroni)
alcuni DET:indef alcunPoS-tagging e lemmatizzazione
Unknown
Possibili motivi : token non riconosciuto, tokenizzazione problematica, sporcizia nel testo (e.g., OCR), ...
TreeTagger (Stein)
"l' ombra del giqante"
l VER:impe <unknown>
' PON '
ombra NOM ombra
del PRE:det del
giqante NOM <unknown>"l'ombra del gigante"
l' DET:def il
ombra NOM ombra
del PRE:det del
gigante NOM gigantePoS-tagging e lemmatizzazione
Omografia
Un lemma può avere più PoS
TreeTagger (Stein). Fuori contesto:
"faccia"
faccia NOM facciaPoS-tagging e lemmatizzazione
Omografia
TreeTagger (Stein). In contesto:
"Ha una brutta faccia "
Ha VER:pres avere
una DET:indef una
brutta ADJ brutto
faccia NOM faccia"Non so come lei faccia "
Non ADV non
so VER:pres sapere
come CON come
lei PRO:pers lei
faccia VER:cpre farePoS-tagging e lemmatizzazione
Omografia
TreeTagger (Stein). Attenzione però! Sempre in contesto:
"Non so come faccia "
Non ADV non
so VER:pres sapere
come PRE come
faccia NOM facciaPoS-tagging e lemmatizzazione
Omografia
TreeTagger (Stein). E ancora in contesto:
"non so con che faccia faccia questa domanda"
non ADV non
so VER:pres sapere
con PRE con
che PRO:rela che
faccia VER:cpre fare
faccia VER:cpre fare
questa PRO:demo questo
domanda VER:pres domandarePoS-tagging e lemmatizzazione
Performance
Alcuni strumenti e modelli più performanti di altri
TreeTagger (Stein)
finché CON finchéfinchè CON finchèTreeTagger (Baroni)
finché CON finchéfinchè VER:fin <unknown>Un tagger addestrato su Petrarca non è adatto all'analisi di italiano contemporaneo e viceversa
Verifica dei dati!
Analisi morfologica
PoS-tagging può estendersi ai tratti morfologici
L'analisi morfologica assegna tratti morfologici alle forme:
- PoS
- genere, numero, persona, modo, tempo, caso, grado, diatesi, etc.
Named Entity Recognition (NER)

Processo di identificazione o estrazione di entità volto a trovare e classificare ogni elemento presente in un testo in categorie predefinite, e.g., persone, organizzazioni, luoghi, eventi, quantità, valute monetarie, percentuali, etc.
Si avvale di tokenizzazione, POS tagging, regole per l’uso delle maiuscole e altre funzioni TAL.
Parsing sintattico

Analisi delle dipendenze fra parole e della struttura della frase
Il parsing viene effettuato da un parser
Parsing sintattico
Parser sintattico si avvale di dati annotati o treebank = corpus annotato a livello sintattico. Solitamente include:
- Lemmatizzazione (disambiguata)
- Tratti morfologici (disambiguati)
- Annotazione sintattica
- Content words sono connesse attraverso dipendenze
- Function words dipendono dalla content word che modificano
- Segni di punteggiatura dipendono dalla testa della proposizione o del sintagma
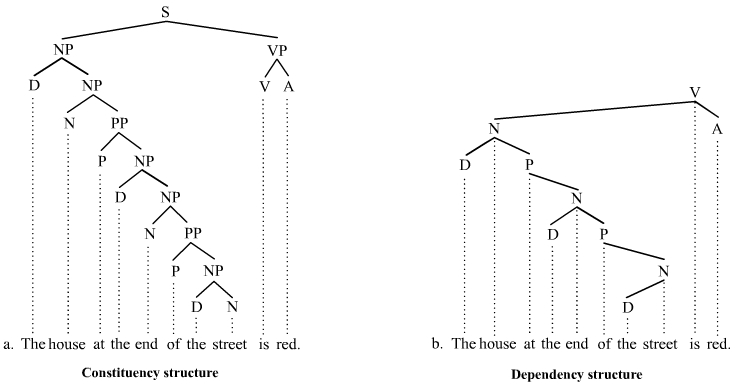
Parsing sintattico
Treebank di due tipi
A costituenti A dipendenze
Parsing semantico

Processo di assegnazione di un significato, un senso, alla struttura sintattica corretta e, di conseguenza, all'espressione linguistica.
Parsing semantico
Parsing semantico comincia con l'analisi delle relazioni fra parole. Questo richiede una conoscenza di:
- gerarchie lessicali, e.g. iperonimia, oponimia, meronimia, olonimia, antonimia, sinonimia, etc. (WordNet). I sensi/concetti sono lessicalizzati per gruppi di sinonimi (synset).
- connotazione (semiotica) e collocazione, ovvero la combinazione di parole che occorrono spesso con una parola, e.g. idiomi, metafore o similitudini come "bianco come un cadavere."
Esempi di parsing semantico:
- Machine Translation
- Semantic role labeling (a.k.a. shallow semantic parsing): processo di assegnazione di etichette semantiche a parole o frasi. Le etichette indicano il ruolo semantico delle parole e delle frasi in un contesto più ampio, e.g. agente, fine e risultato.
TAL per italiano delle origini
Come siamo messi?
...non benissimo... perché?
Perché i dati (annotati) non sono accessibili = non si possono addestrare altri modelli o strumenti di analisi!

Linea/riga di comando (CLI)
Nota anche come "terminale" in sistemi Unix.
Una console o interfaccia utente per impartire comandi di elaborazione alla macchina
Linea/riga di comando (CLI)
Perché usarla?
Ai fini di TAL, e.g.:
- Preparazione dei dati con RegEx (Regular Expressions)
- Regular Expressions (= espressione regolare) sequenza di simboli (quindi una stringa) che identifica un insieme di stringhe
- Lancio di strumenti (e.g., TreeTagger, LEMLAT, TRACER, etc.)
- Capire come funzionano strumenti analoghi (e.g. web) di analisi testuale
- Interazione con computer portatili e server
Pratica
Requisiti
Quanti Windows e quanti Mac/Linux?
Requisiti
Controllo installazioni
- Windows
- Cygwin (per esercitazioni con linea di comando)
- Command Prompt (per TreeTagger)
- Windows, Mac, Linux
- Sublime Text Editor 3
- TreeTagger
- Parameter files per l'italiano (Stein e Baroni)
- Pacchetto Tagger
- Tagging scripts
- install-tagger.sh
- Mac
- Homebrew
Esercizi
- Navigazione file di sistema
- Calcolo della ricchezza lessicale
- Lancio di TreeTagger
File di testo forniti per esercitazioni (2 e 3):
- Due alchimisti italiani, Racconti storici e morali, di Cesare Cantù (1878)
- Che cos'è il mondo, Novelle, di Adolfo Albertazzi (1940)
D'ora in poi ci si riferirà alla linea di comando come CLI
E.1: Navigazione file di sistema
- Spostamento fra directory
- Creazione e rimozione di file e cartelle
- Rinomina e copia di file e cartelle
E.1: Navigazione file di sistema
Apri la CLI
E.1: Navigazione file di sistema
Present working directory: pwd
greta$ pwdMostra la mia posizione attuale
greta$ pwd
/Users/gretaE.1: Navigazione file di sistema
ls -lgreta$ ls -lMostra la lista dei contenuti della directory attuale
$ total 352
drwx------@ 6 greta staff 204 22 Dic 2018 Applications
drwx------+ 17 greta staff 578 23 Giu 15:03 Desktop
drwx------+ 5 greta staff 170 13 Gen 15:27 Documents
drwx------+ 19 greta staff 646 23 Giu 13:55 Downloads
...E.1: Navigazione file di sistema
Cambia directory: cd <directory>
greta$ cd DesktopMi sposto sul Desktop
Desktop greta$E.1: Navigazione file di sistema
Cambia alla directory precedente: cd ..
Desktop greta$ cd ..Mi riporta a greta
greta$E.1: Navigazione file di sistema
Cambia directory, azzera: cd
Sono qui
/Users/greta/Desktop/cad/corpus-italian-shortstoriesVoglio tornare alla directory greta
corpus-italian-shortstories$ cd
greta$E.1: Navigazione file di sistema
Crea un file: touch <file.txt>
$ cd Desktop
Desktop greta$ touch ciao.txtMi crea un file di testo intitolato ciao.txt
Desktop greta$ ls -l
-rw-r--r-- 1 greta staff 0 23 Giu 21:24 ciao.txt
...E.1: Navigazione file di sistema
Crea una cartella: mkdir <cartella>
$ cd Desktop
Desktop greta$ mkdir poesieMi crea una cartella intitolata poesie
Desktop greta$ ls -l
drwxr-xr-x 2 greta staff 68 23 Giu 21:37 poesie
...E.1: Navigazione file di sistema
Rinomina un file: mv oldname.txt newname.txt
greta$ mv ciao.txt CIAO.txto una cartella: mv oldname newname
greta$ mv poesie PROSAE.1: Navigazione file di sistema
Elimina un file: rm file.txt
greta$ rm ciao.txto una cartella: rmdir foldername
greta$ rmdir poesieE.1: Navigazione file di sistema
Fai una copia di un file in un'altra directory:
cp filename.txt foldername
greta$ cp ciao.txt poesieE.1: Navigazione file di sistema
Per ripulire lo schermo:
clear
greta$ clearE.2: Calcolo della ricchezza lessicale
Nota come Type/Token Ratio (TTR)
Qualche idea su come si faccia?
(Types/Tokens) * 100 = N%
Più alta la ratio, più ricco il lessico
E.2: Calcolo della ricchezza lessicale
Nella CLI, spostati nella directory dove sono stati scaricati i due file di testo e apri il file:
cat cantu_due-alchimisti-italiani_1878.txt
greta$ cat cantu_due-alchimisti-italiani_1878.txtE.2: Calcolo della ricchezza lessicale
Minuscolizza tutto il testo:
tr '[:upper:]' '[:lower:]'
greta$ cat cantu_due-alchimisti-italiani_1878.txt | tr '[:upper:]' '[:lower:]'E.2: Calcolo della ricchezza lessicale
Trasforma la punteggiatura in un ritorno a capo:
tr '[:punct:]' '\n'
greta$ cat cantu_due-alchimisti-italiani_1878.txt | tr '[:upper:]' '[:lower:]' | tr '[:punct:]' '\n'E.2: Calcolo della ricchezza lessicale
Trasforma gli spazi in un ritorno a capo:
tr '[:space:]' '\n'
greta$ cat cantu_due-alchimisti-italiani_1878.txt | tr '[:upper:]' '[:lower:]' | tr '[:punct:]' '\n' | tr '[:space:]' '\n'E.2: Calcolo della ricchezza lessicale
Rimuovi tutte le righe vuote:
sed '/^\s*$/d'
greta$ cat cantu_due-alchimisti-italiani_1878.txt | tr '[:upper:]' '[:lower:]' | tr '[:punct:]' '\n' | tr '[:space:]' '\n' | sed '/^\s*$/d'E.2: Calcolo della ricchezza lessicale
Salva i risultati in un nuovo file:
> cantu_due-alchemisti-italiani_1878.txt.tokens
greta$ cat cantu_due-alchimisti-italiani_1878.txt | tr '[:upper:]' '[:lower:]' | tr '[:punct:]' '\n' | tr '[:space:]' '\n' | sed '/^\s*$/d' > cantu_due-alchemisti-italiani_1878.txt.tokensE.2: Calcolo della ricchezza lessicale
Calcola il numero totale di token:
wc -l cantu_due-alchemisti-italiani_1878.txt.tokens
greta$ wc -l cantu_due-alchemisti-italiani_1878.txt.tokensE.2: Calcolo della ricchezza lessicale
Apri il file dei tokens:
cat cantu_due-alchimisti-italiani_1878.txt.tokens
cat cantu_due-alchimisti-italiani_1878.txt.tokensE.2: Calcolo della ricchezza lessicale
Ordina i token alfabeticamente:
sort
cat cantu_due-alchimisti-italiani_1878.txt.tokens | sortE.2: Calcolo della ricchezza lessicale
Rimuovi i duplicati:
uniq -c
cat cantu_due-alchimisti-italiani_1878.txt.tokens | sort | uniq -cE.2: Calcolo della ricchezza lessicale
Salva i risultati in un nuovo file:
> cantu_due-alchimisti-italiani_1878.txt.types
cat cantu_due-alchimisti-italiani_1878.txt.tokens | sort | uniq -c > cantu_due-alchimisti-italiani_1878.txt.typesE.2: Calcolo della ricchezza lessicale
Calcola il numero totale di type:
wc -l cantu_due-alchemisti-italiani_1878.txt.types
greta$ wc -l cantu_due-alchemisti-italiani_1878.txt.typesE.2: Calcolo della ricchezza lessicale
Calcola la TTR:
(Types/Tokens) * 100 = N%
Ripeti l'esercizio per
albertazzi_il-mondo_1940.txt
E.3: TreeTagger
MAC, Linux e Windows:
- Scaricare pacchetto tree-tagger sul Desktop, estrarre lo zip e rinominare la cartella a treetagger
- Estrarre contenuti di tagger-scripts.tar.gz
- Scaricare e estrarre i due modelli italiani nella cartella treetagger/tagger-scripts/lib
- Scaricare il modello italian-dhante.par dal sito CAD nella cartella treetagger/tagger-scripts/lib
- Aggiunta del parametro Dhante e Baroni
E.3: TreeTagger
Posizionarsi in Desktop/treetagger .
Poi, in MAC e Linux:
Per taggare un testo con parametro Stein:
treetagger greta$ cat testo.txt | cmd/tree-tagger-italian > testo.taggedPer taggare un testo con parametro Baroni:
treetagger greta$ cat testo.txt | cmd/tree-tagger-italian2 > testo.taggedPer taggare un testo con parametro Dhante:
treetagger greta$ cat testo.txt | cmd/tree-tagger-italian-dhante > testo.taggedE.3: TreeTagger
In Windows (Command Prompt):
Sostituire cat con type :
treetagger greta$ type testo.txt | cmd/tree-tagger-italian > testo.taggedE.3: TreeTagger
Sull' output di TreeTagger:
- estrai tutti gli unknown e salvali in un file separato (grep)
- ordina unknown alfabeticamente
- ordina unknown per PoS ( sort -k 2 )
- che problemi noti?
Risorse e Strumenti
Evalita
Iniziativa dell'Associazione Italiana di Linguistica Computazionale (AILC) volta alla valutazione di strumenti NLP per l'italiano
Strumenti
- Tint: Pipeline NLP
- ItaliaNLP: Pipeline NLP
- Text Analysis Online
- CATMA: Textual Markup and Analysis
- NLTK: Natural Language Toolkit
- SpaCy: Pipeline NLP
- OpenNLP: Pipeline NLP
- UDPipe: Pipeline NLP
- Orange Text Mining
- Open Parallel Corpus
- Voyant tools: Text analysis
Tutorial e mailing List
Tutorial
Mailing list
Risorse testuali
Italiano delle origini
Mappa dei comandi
| Windows | Descrizione | Mac/Linux |
dir |
Mostra contenuti | ls |
cd |
Mostra posizione attuale | pwd |
cd path/to/directory |
Cambio directory | cd path/to/directory |
cd.. |
Indietro di una directory | cd .. |
cd |
Torna alla root directory | cd / |
mkdir nuovaCartella |
Crea una nuova cartella | mkdir nuovaCartella |
echo some-text > fileName(.txt) |
Crea un nuovo file | touch fileName(.txt) |
rmdir myFolder |
Rimuovi una cartella* | rmdir myFolder |
ren oldFolderName newFolderName |
Rinomina una cartella | mv oldFolderName newFolderName |
robocopy myFolder path/to/destination/directory |
Copia una cartella | cp -r myFolder path/to/destination/directory |
move myFolder path/to/destination/directory |
Sposta una cartella | mv myFolder path/to/destination/directory |
del myFile |
Rimuovi un file* | rm myFile |
ren oldFileName newFileName |
Rinomina un file | mv oldFileName newFileName |
copy myFile path/to/destination/directory |
Copia un file | cp myFile path/to/destination/directory |
move myFile path/to/destination/directory |
Sposta un file | mv myFile path/to/destination/directory |
cls |
Pulisci la schermata | clear |
type |
Apri un file | cat |
type C:/../myFile.txt| find "" /v /c |
Conta righe di un file | wc -l myFile(.txt) |
*ATTENZIONE: il comando di rimozione NON chiede conferma all'utente.